Der Crawling Bedarf wird hingegen vorwiegend von Komponenten bestimmt, die den Inhalt/Content einer Seite betreffen. Hier spielen zum Beispiel die Relevanz, die Aktualisierungshäufigkeit und die Seitenqualität eine Rolle. Zusätzlich kommt es auch auf die Größe der Website an.
Google selbst nennt drei Faktoren, die für die Bestimmung des Crawling-Bedarfs verwendet werden:
- Wahrgenommenes Inventar
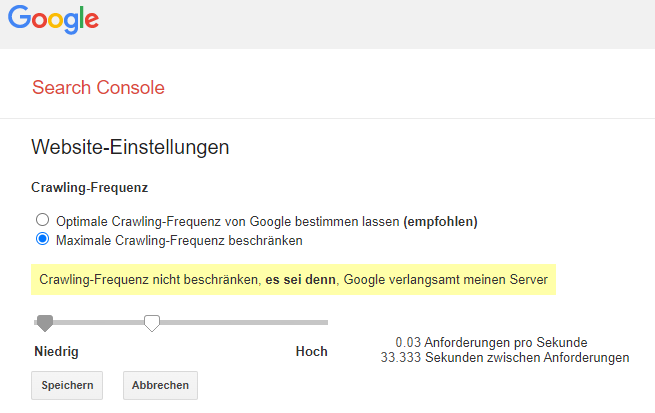
Darunter fallen Duplikate, entfernte Seiten oder unwichtige Seiten, welche viel Zeit beim Crawling verbrauchen und damit Crawling-Budget verschwenden. Google sieht das nicht gern, weshalb sich obsolete Inhalte negativ auswirken. Hier können Websiteinhaber aber selbst einige wichtige Einstellungen treffen, welche weiter unten erklärt werden. - Beliebtheit
URLs die sehr beliebt sind, möchte Google aufgrund ihrer Popularität auch im Index aktuell halten und crawlt diese deshalb häufiger. - Aktualität
Google will seinen Nutzern wichtige Änderungen natürlich nicht vorenthalten und versucht deshalb zu verhindern, dass sich veraltete URLs im Index befinden.
Hierzu gibt es auch von John Müller zwei aktuelle Aussagen:
Zum einen erklärte er in den Google Search Central SEO Office Hours vom 18. Februar, dass der größte Anteil des Crawlens für die Aktualisierung bestehender Inhalte verwendet wird.
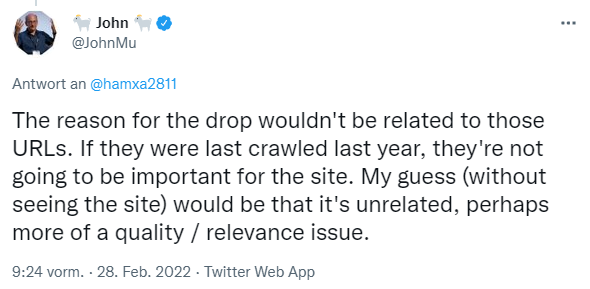
Zum anderen antwortete er auf die Frage, warum die Seite eines Websiteinhabers auf einmal weniger Klicks aus der Suche erhalte mit folgendem Tweet:
Das Datum des letzten Crawlens kann also einen Hinweis darauf geben, für wie wichtig Google eine Seite hält.
Zusammengefasst wird das Crawl-Budget also von der Kapazität, die ein Crawler auf einer Website aufwenden möchte und der Menge an Crawling-Anfragen die der Server der Website unterstützen kann, beeinflusst.